Welcome to WiserSpeech: Empowering Your Products and Services with Advanced Speaker Identification Solutions
About Us:
At WiserSpeech, we specialize in providing cutting-edge Speaker Identification solutions to businesses, enabling them to enhance security, personalize user experiences, and improve customer interactions. Our expertise lies in developing robust AI models, integrating APIs, and utilizing advanced Speech Enhancement and Feature Extraction techniques to ensure accurate and reliable Speaker Identification.
Speaker Identification Process:
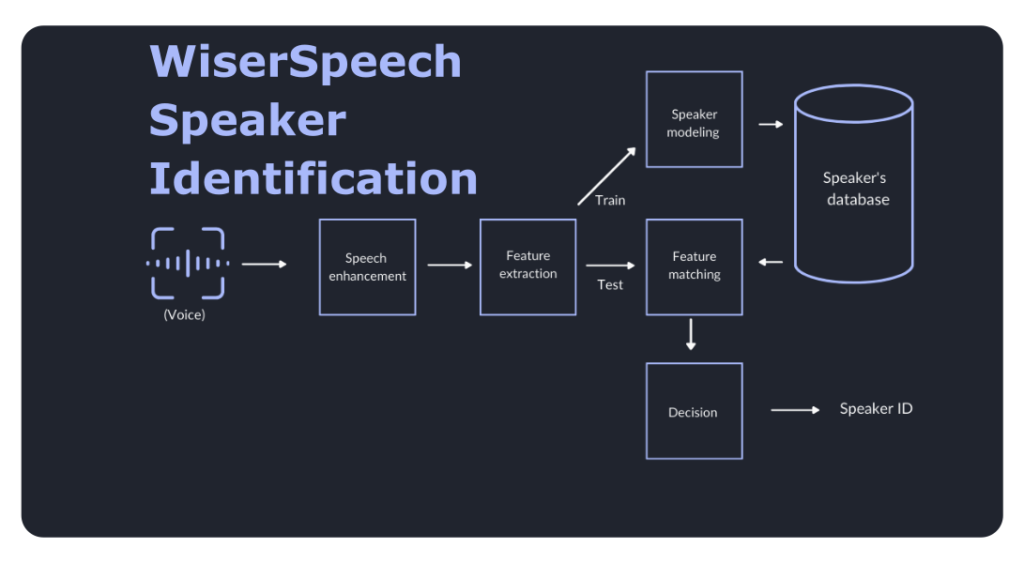
The Speaker Identification process involves several crucial steps to recognize and verify individuals based on their voice:
- Speech Enhancement: Our advanced Speech Enhancement techniques are used to improve the quality of the input audio. This process reduces background noise, echo, and other distortions, ensuring cleaner audio for accurate speaker analysis.
- Feature Extraction: In this step, relevant acoustic features are extracted from the enhanced audio signals. Mel-frequency cepstral coefficients (MFCCs), spectral features, and prosodic features are some of the representations used to capture unique characteristics of a speaker’s voice.
- Speaker Database: To perform identification, a speaker database is created, consisting of enrolled speaker voiceprints. Each voiceprint contains the unique acoustic features and characteristics of a particular speaker.
- Speaker Modeling: The extracted acoustic features from the input audio are compared against the voiceprints in the speaker database. Speaker modeling involves training machine learning models to discriminate between different speakers and map the input audio to the most likely speaker identity.
- Decision Maker: The decision-making process involves selecting the most probable speaker identity based on the comparison between the input audio and the speaker database. Confidence scores or likelihood ratios are used to determine the match.
Our Services:
- Speaker Identification Integration: We seamlessly integrate Speaker Identification capabilities into your applications, providing secure and accurate speaker recognition. Our solutions are designed to suit various industries, including security, customer service, and personalization.
- Custom Speaker Modeling: Our AI experts develop customized speaker modeling solutions tailored to your specific use case. Whether it’s speaker verification or identification, we ensure optimal performance and precision.
- Speaker Identification API: Easily integrate our powerful Speaker Identification API into your platforms and applications. Our well-documented APIs make integration a breeze.
- Continuous Support and Improvement: We are committed to delivering reliable and high-performing Speaker Identification solutions. Our team provides ongoing support and regularly updates the models to adapt to changing needs.
Demo:
For demo please contact us.
Contact Us:
For inquiries, custom Speaker Identification solutions, or to discuss how WiserSpeech can elevate your speaker recognition capabilities, contact our team at info@wiserli.com.
About WiserSpeech:
At WiserSpeech, we are driven by the passion to deliver state-of-the-art Speaker Identification solutions. Our mission is to empower businesses with AI-driven technology, enabling them to leverage the power of voice for enhanced security and customer interactions.
Disclaimer: Speaker Identification accuracy may vary depending on factors such as audio quality, speaker variability, and size of the speaker database. We continually strive to improve our models to provide the best possible performance.