Welcome to WiserSpeech: Advanced Speech Enhancement Models
Overview:
The WiserSpeech’s Enhancement models, where cutting-edge speech enhancement technology meets superior performance. Our state-of-the-art models, WiserSpeechEnhance1 and WiserSpeechEnhance2, rival the best in the industry, including DeepFilterNet 2, DeepFilterNet 3, SpeechBrain, and more. With our custom and advanced algorithms, we are dedicated to delivering exceptional speech enhancement results, making audio processing a breeze.
Key Features:
- Unmatched Performance: WiserSpeechEnhance1 and WiserSpeechEnhance2 have been meticulously designed and trained to achieve unmatched performance in speech enhancement, see the table below. Experience crystal-clear audio quality and reduced background noise like never before.
- Versatility: Our models are capable of handling various noise types and can adapt to different environments, from bustling urban spaces to outdoor settings. Whatever your scenario, WiserSpeech has got you covered.
- Real-Time Processing: Enjoy real-time audio processing capabilities with WiserSpeech. Our models are optimized for speed and efficiency, making them suitable for live applications, virtual conferencing, and more.
- Multichannel Support: We also offer multichannel support, allowing it to process and enhance audio from multiple microphones or audio sources simultaneously. With this, you can expect consistent and high-quality audio enhancement across all channels, further enhancing the overall audio experience.
- Easy Integration: Seamlessly integrate WiserSpeech into your existing projects and workflows. Our user-friendly interface and well-documented APIs ensure smooth integration, regardless of your level of technical expertise.
- Continuous Improvements: We are committed to constant research and development, continuously enhancing the performance of our models. Expect regular updates and improvements to take your speech enhancement experience to the next level.
| Model | PESQ | CSIG | CBAK | COVL | STOI |
|---|---|---|---|---|---|
| RDL-Net 3.91M | 3.02 | 4.38 | 3.43 | 3.72 | |
| DeepFilterNet2 | 3.08 | 4.30 | 3.40 | 3.70 | 0.943 |
| WiserSpeechEnhance1 | 3.15 | 4.34 | 3.54 | 3.77 | 0.943 |
| SpeechBrain | 3.15 | 0.930 | |||
| WiserSpeechEnhance2 | 3.16 | 4.31 | 3.39 | 3.75 | 0.943 |
Metrics Description:
PESQ – Perceptual Evaluation of Speech Quality (wide-band version in ITU-T P.862.2, from −0.5 to 4.5)
CSIG – Mean Opinion Score (MOS) prediction of speech distortion (from 1 to 5)
CBAK – MOS prediction of background noise interference (from 1 to 5)
COVL – MOS prediction of overall effect (from 1 to 5)
STOI – Short-Time Objective Intelligibility (from 0 to 1)
all these metrics are better if higher.
Demo:
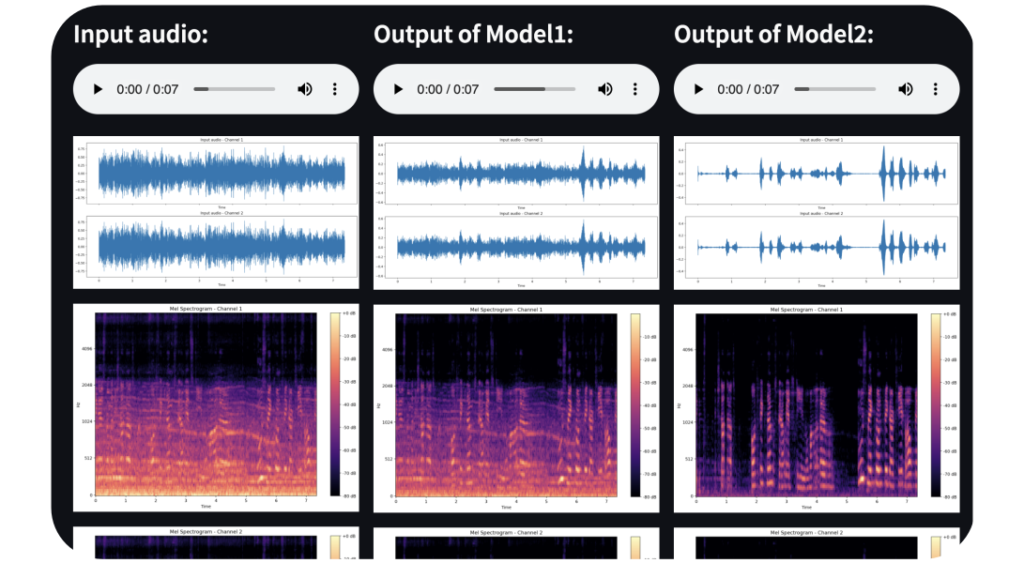
Try WiserSpeech Now:
Ready to witness the transformative power of WiserSpeech? Try our live demo now by clicking here. Upload your audio samples and see how WiserSpeechEnhance1 (Model1) and WiserSpeechEnhance2 (Model2) can elevate your speech quality instantly, there is also WiserSpeechEnhance3 (Model3) which is variant of WiserSpeechEnhance2.
Use Cases:
- Telecommunications: Enhance voice calls, video conferences, and virtual meetings by eliminating background noise and ensuring crystal-clear communication.
- Media Production: Improve audio quality in podcasts, videos, and other media productions for a professional and engaging end-user experience.
- Voice Assistants: Optimize speech input processing for voice assistants, ensuring accurate and efficient voice recognition.
Contact Us:
For inquiries, custom solutions, or any questions, please reach out to our team Wiserli at info@wiserli.com.
About Us:
WiserSpeech is brand of Wiserli, we are passionate about leveraging cutting-edge speech and language technology to enhance and transform speech experiences. Our team of experts is dedicated to pushing the boundaries of speech enhancement, providing you with top-notch solutions for your audio needs.
Disclaimer: While WiserSpeechEnhance delivers exceptional results in speech enhancement, it may not completely remove all audio artifacts or background noise in every circumstance.