Welcome to WiserSpeech: Your One-Stop Solution for Speech Recognition Services and AI Model Integration
About Us:
At WiserSpeech, we are dedicated to helping businesses integrate advanced Speech Recognition capabilities into their products and services. Our expertise lies in providing top-notch Automatic Speech Recognition (ASR) solutions, building AI models, and offering seamless API integration. Whether you need to enhance your existing ASR system or develop a brand-new application, we have the tools and expertise to make it happen.
Speech Recognition Process:
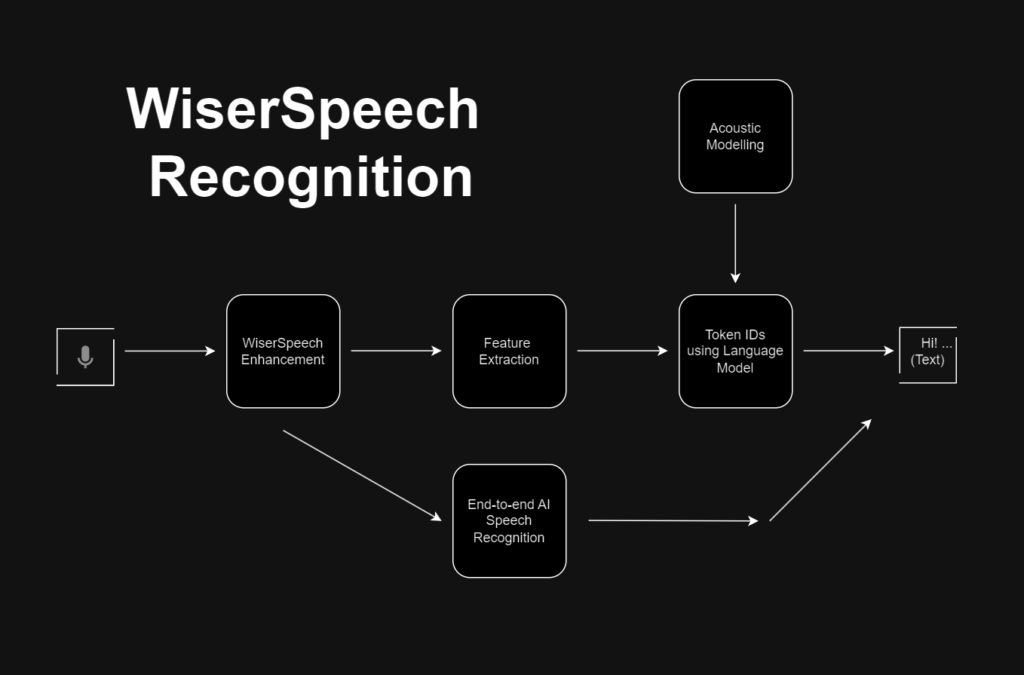
The Speech Recognition process involves several key steps to convert spoken language into text:
- Speech Enhancement: We employ advanced Speech Enhancement techniques to improve the quality of input audio, reducing background noise and interference. This ensures more accurate recognition results by providing cleaner audio to the ASR system.
- Feature Extraction: In this step, relevant features are extracted from the enhanced audio signals. Mel-frequency cepstral coefficients (MFCCs) and other acoustic features are commonly used to represent the characteristics of the speech.
- Language Model and Tokenization: Language models play a crucial role in Speech Recognition. They help to predict the probability of word sequences and guide the decoding process. Tokenization involves breaking down the input text into smaller units (tokens) for better modeling and recognition.
- Acoustic Modeling vs. End-to-End Language Model: Acoustic Modeling involves training models to map acoustic features to phonemes or subword units, which are further combined to form words. This traditional approach requires a separate language model for the final recognition. On the other hand, End-to-End Language Models directly predict word sequences from audio without the need for separate components, simplifying the pipeline and potentially improving accuracy.
Our Services:
- ASR Integration: We provide seamless integration of ASR capabilities into your existing products and services, enabling real-time speech-to-text conversion. Enhance user interactions, automate transcription tasks, and enable voice commands with our robust ASR solutions.
- Custom AI Model Building: Our team of AI experts can develop customized Speech Recognition models tailored to your specific domain and requirements. Whether it’s industry-specific jargon or specialized vocabulary, our models are designed to deliver accurate results.
- API Integration: Easily integrate our powerful ASR APIs into your web or mobile applications. Our well-documented APIs make the process straightforward, even for non-technical users.
- Continuous Support and Improvement: We are committed to delivering reliable and high-performing ASR solutions. Our team provides ongoing support and regularly updates the models to adapt to changing needs.
Demo:
For demo please contact us.
Contact Us:
For inquiries, custom ASR solutions, or to discuss how WiserSpeech can elevate your speech recognition capabilities, contact our team at info@wiserli.com.
About WiserSpeech:
At WiserSpeech, we are driven by the passion to deliver state-of-the-art Speech Recognition solutions. Our mission is to empower businesses with AI-driven technology, helping them leverage the power of speech for enhanced user experiences and business growth.
Disclaimer: Speech Recognition accuracy may vary depending on factors such as audio quality, vocabulary, and domain-specific language. We continually strive to improve our models to provide the best possible performance.